OpenMined was delighted to respond to the United States National Telecommunications and Information Administration (NTIA) request for comment on dual use foundation AI models with widely available model weights.
Our comments can be found in full here. A portion of them are reproduced below.
“Today, AI developers face a difficult binary choice: whether to open-source their models or keep them closed-source. Such a decision presents many tradeoffs for either choice. Open-sourcing an AI model activates all use and misuse possibilities, whereas keeping a model closed-source limits it to only uses or misuses allowed by a corporation. As such, the decision is actually about who to trust with the use vs. misuse decision: trust AI developers (i.e., closed source) or anyone who might download an AI model (i.e., open source). Neither option is optimal.
Third Choice – Use decided by Flexible Representative Stakeholder Groups
Our comments will instead present a third option: use/misuse, according to a representative stakeholder group, made possible through two technical methods: secure enclaves and retrieval-based deep learning1.
1. Secure Enclaves for Representative Governance
Key Concern — Who Controls Model Governance?
A key concern surrounding the open vs. closed debate is that when AI models remain closed-source, AI companies retain unilateral control over them. This governance model inhibits important stakeholders and perspectives from being considered in AI model governance decisions.
Brief Technical Description
Secure enclaves are a technical solution that can offer the “best of both worlds” aspects of open and closed-source governance models. As a piece of technology, they are a new type of computer chip manufactured with a cryptographic private key inside. As a core attribute of most enclaves, no one can get to that key without breaking the chip, such that (in theory) no one can obtain the key.
This property has profound implications. The secrecy of this key means that external parties can encrypt data in a way that only this chip—with only this key—can decrypt. When an enclave is attached to the internet, multiple parties can send data from around the world to the enclave and be confident that their data can only be decrypted inside the enclave.
Furthermore, as an enclave performs computation, it must save its incremental work into Random Access Memory (RAM). When it does so, it first encrypts its results before sending them to RAM, which means no one — not even the enclave’s administrator — can see the program being run. Such a technical guarantee can give external parties the confidence to send software and data to a secure enclave in the cloud — and be confident that not even the cloud provider can see their software or data or know what the enclave is doing.
Finally, enclaves have another special property: attestation. When an enclave runs a piece of software, it produces a cryptographic hash (i.e., unique fingerprint) of the software that runs at all times. This means that at any moment, someone who is relying upon the computation can check to see whether the software in the enclave is as expected2.
While avoiding some technical specifics, the combination of these properties produces something greater than the sum of its parts. Multiple people can agree upon a piece of software they want to run together. They can encrypt both their unique part of the software and their distinct input data and send it to an enclave, on which they know the enclave will reliably produce outputs that only the expected party (as determined by the software everyone agreed upon) can read. Taken together, multiple parties can jointly compute a result while ensuring that the only party who learns anything is the person whom the software specifies to see the result.
Implications — Possibilities for Shared & Representative Governance
Secure enclaves have profound implications for the open vs. closed-source AI debate in that they open up the potential for shared and representative governance over AI models. Instead of fully open or close-sourcing a model, companies can elect to share governance with a representative pool of stewarding stakeholders whose purpose is to weigh the pros and cons of use in each specific context and come to the best decision. Then, the decision can be enforced through a secure enclave.
For example, take Company A, which owns a dual-use foundation AI model with closed model weights, which we will refer to as Model A. Right now, Company A has unilateral control over who can use Model A for fine-tuning or any other purpose. Company A decides what the definition of use and misuse is for Model A because it owns Model A.
However, in a world where Company A, voluntarily or by some other means, loads Model A into a secure enclave, they can then introduce flexible governance frameworks for control over Model A.
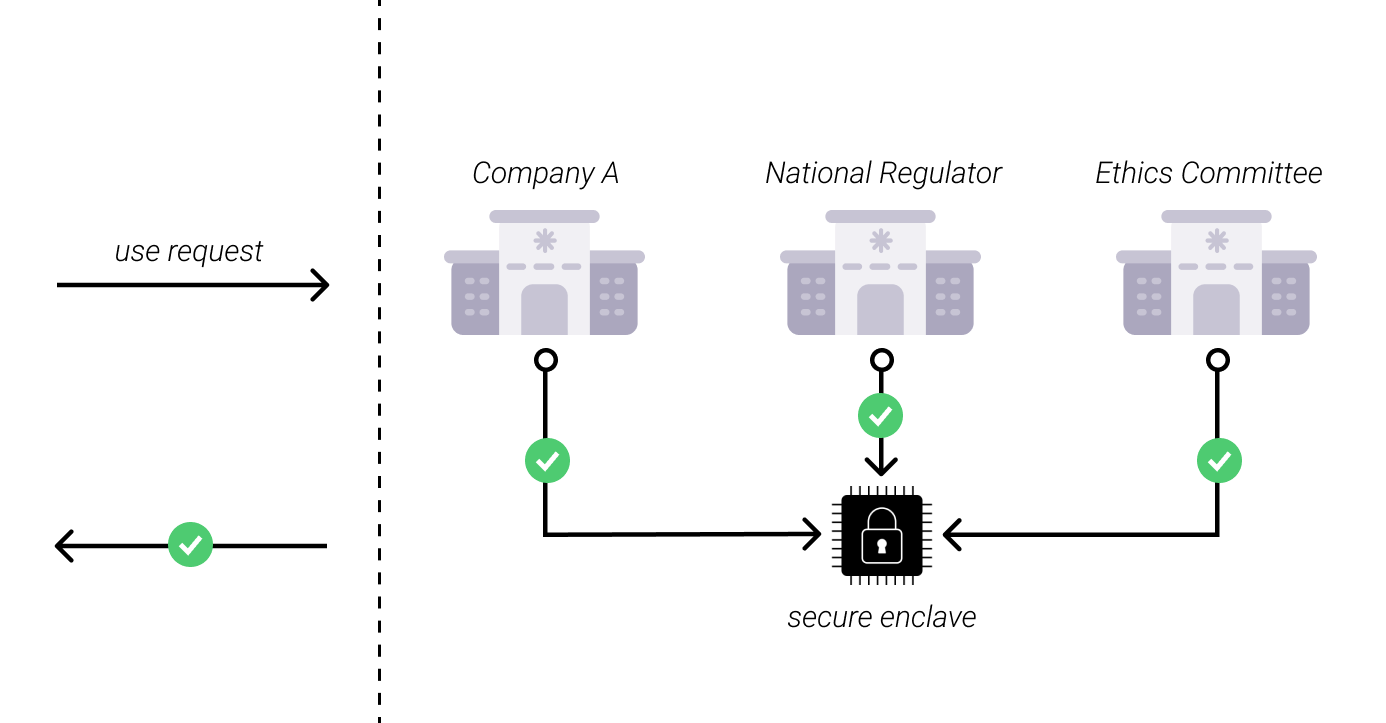
One such framework could include shared control with a national regulator and an ethics committee that apply their distinct and unique definitions of use and misuse of Model A based on the mission and authorities of such entities, and then use is only permitted if two or more, of the three governance entities approve the use.
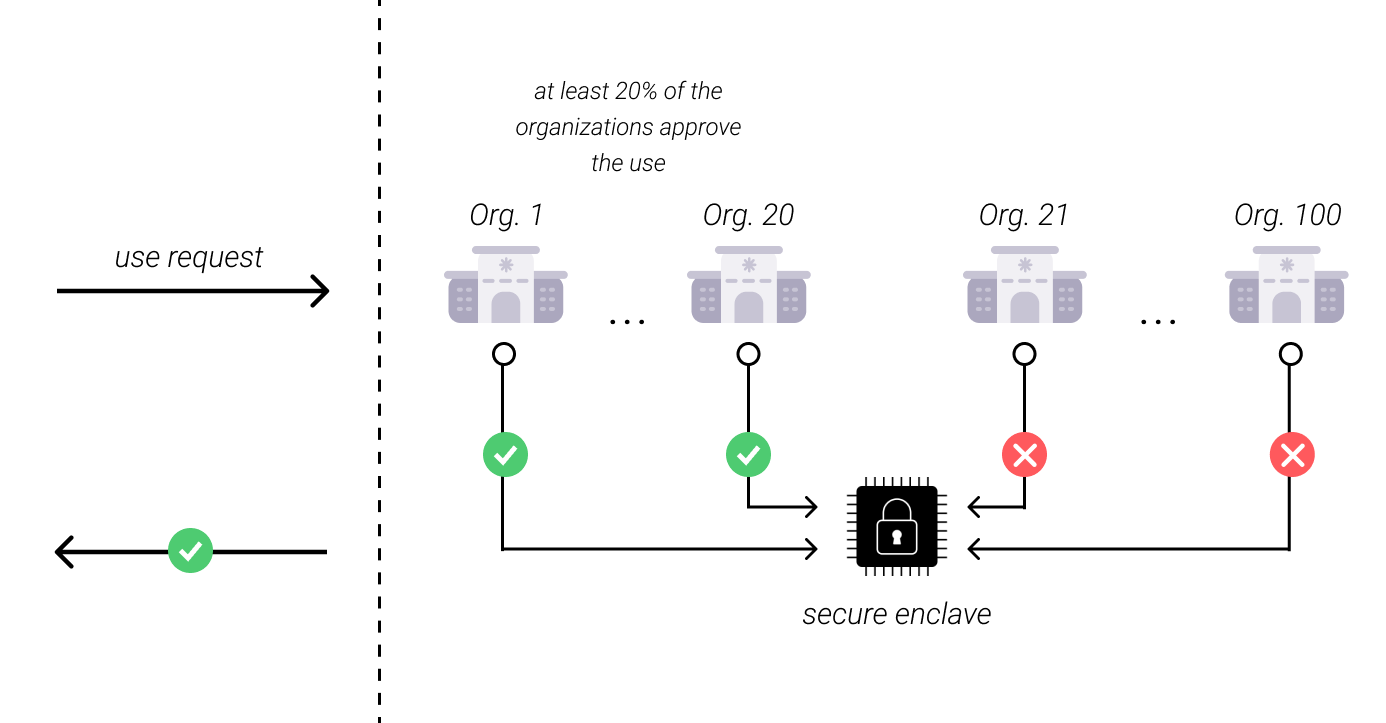
Another such framework could include thousands (or any number) of individual participants where the use of Model A is only permitted if X% of the participants approve the use.
As briefly described in the above illustrative frameworks, secure enclaves make myriad configurations of governance frameworks possible. Secure enclaves are merely a technical solution to enforce policy definitions about use and misuse, and the NTIA should consider who should create those definitions in its report.
Redefining What it Means to Be Open
Now, proponents of open-source AI might argue that this third option is merely another form of closed-source AI, as it only works if a copy of an AI model is not readily available for open download. However, while secure enclaves could certainly be used to facilitate closed-source style governance, we invite proponents of open-source AI to reconsider.
In the limit, a shared governance model enforced through secure enclaves of a technically closed-source AI model can feel like an open-source model if a highly interactive governance framework composed of enough reviewers or automatic review infrastructure is deployed to make use/misuse decisions seem instantaneous3. Within the frame of this third option, whether an AI model feels open source or closed source actually comes down to who gets to participate in the governance process. It comes down to representation—and this operates on a spectrum.
On one end of the spectrum is a version of the example explained above, where Company A loads Model A into a secure enclave, and a second entity shares governance over the model based on some decision-making criteria. In this model, one company still retains mostly exclusive and unilateral control over its AI model. The use of an enclave has not changed the actual governance to be representative since it’s a voting pool of merely two entities. Thus, even though an enclave is present, it’s still fundamentally a closed-source AI.
On the other end of the spectrum would be Company A, still loading Model A into a secure enclave, but this time, the entire country is able to participate in the governance process4. In the least restrictive setting, if any two participants out of potentially millions of democratic participants decide to approve an AI’s specific use, the use would proceed. Given the sheer number of participants and the incredibly low threshold for approval, Model A would feel open-source because use would almost never be denied. The gradient between one party and any large defined demographic can be technically specified through secure enclaves to technically implement a gradient of openness5. As such, this third option fills the gap between open and closed, empowering stewarding bodies with the ability to specify the governing coalitions they feel will lead to the greatest use and the least misuse. And it is that responsibility – and that creativity — that we hope the NTIA will embrace.
2. Retrieval Models for Unbundled Capabilities
Key Concern — Models with Bundled Capabilities
Presently, dual-use foundation AI models ship out to production environments with a huge bundle of capabilities that have the potential to create both benefit and harm6. Open-source advocates emphasize capabilities that produce benefits, while closed-source advocates emphasize capabilities that produce harm; both try to mitigate the trade-off by declaring that their side is more significant than the other7. In an ideal world, AI models could be open-sourced with all their benefits and none of the harms.
Brief Technical Description
One way of reaching this ideal world is to design AI models with partitioned capabilities — such that a model could separate “safe” capabilities from “unsafe” capabilities into different literal sections of the model8. This theoretical approach can already be approximated through retrieval-based deep learning9.
For example, when OpenAI released Generative Pre-trained Transformer 3 (GPT-3), DeepMind published a paper on its Retrieval-Enhanced Transformer (RETRO). While OpenAI trained GPT-3 as a large, black-box (i.e., bundled capability) model with over a hundred billion parameters, DeepMind trained a model that was 1/25th the size because instead of the model memorizing a huge amount of knowledge into its black-box weights, it learned how to fetch the information it needs from a database. Put another way, RETRO was 96% smaller because the information that would have been stored in the model’s weights was moved into a text database — and RETRO instead learned how to fetch what it needed from the database to respond to user queries.
Despite this architectural change, the DeepMind team achieved a performance comparable to that of GPT-3.
This implies that RETRO has three important characteristics:
- RETRO reveals what sources it uses to respond to queries — because it reveals which text it fetches from the database in the process of responding. This opens up new possibilities for model transparency and accountability.
- RETRO’s knowledge of the world is organized in divisible rows of a database, meaning that knowledge can be modified, excluded (i.e., close-sourced), or revealed (i.e., open-sourced) with ease.
- In a way, RETRO can be “re-trained” without spending tens of millions of dollars because the database can be modified (even swapped with entirely different data). Therefore, it is not prohibitively expensive for any company to implement (minutes-to-hours on a single CPU instead of weeks-to-months across a massive GPU cluster).
Implications — Partition Capabilities Based on Risk
Given its ability to partition capabilities into different sections of the model, retrieval-based deep learning has profound implications for the open vs. closed debate.
For example, let’s say Model B is a dual-use foundation AI model trained through retrieval-based deep learning and owned by Company B. Company B is worried that the model might be used to create a bio-weapon. Since Company B trained Model B as a retrieval system, Company B can exclude its knowledge of biology from the database from which the model retrieves its knowledge and open-sources the rest of the model.
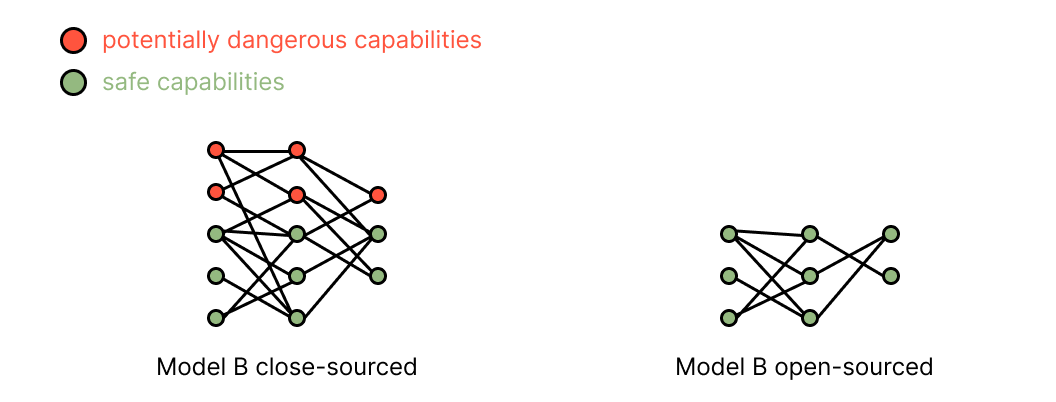
That is to say, if a company wants to open-source a model that might have dangerous capabilities, it could instead focus on open-sourcing just the parts of the model that are unlikely to be dangerous.
3. Retrieval Models with Shared Governance through Secure Enclaves
Finally, without loss of generality, these two approaches can be combined. A model’s capabilities can be partitioned into different sections through retrieval-based deep learning. For example, a model might have a “biology” section, which might be capable of creating biological weapons, or a model might have a “cybersecurity” section, which might be capable of creating malware. Using secure enclaves, each of these sections could be governed by a representative group of stakeholders that are equipped to make use/misuse decisions given a particular context of use. In this way, different types of capabilities can be put into control scenarios wherein use is maximized, and misuse is minimized.
Both technical solutions and their combination are still in the early stages of research and development, going through proof-of-function pilots. The end-to-end system described in both solutions does not yet exist, but most of the individual pieces of technology necessary to power such a system do exist and are ready for pre-deployment testing. With proper investment, enough peer-reviewed research has been done to indicate that both solutions could be ready for production scale in two to three years.
Considerations
The debate between open and closed-source AI exists to reconcile difficult tradeoffs between the use and misuse of such systems. Our comments introduce two technical solutions that provide mitigations for such a tradeoff in that they release the technological constraints surrounding the open vs. closed debate and refocus the debate around the core topic—in a perfect world, how should such powerful resources be governed?
On the technical side, continued investment in research and development is needed to advance such technologies and make them production-ready and scalable. NTIA should encourage the Biden Administration to work with its science agencies and advance the state-of-the-art of these cutting-edge technologies (i.e., secure enclaves and retrieval models). Additionally, companies running pilots and experiments with advanced PETs, like secure enclaves, need legal clarity to continue their research and ultimately ship it into production. NTIA should recommend the Biden Administration work with its privacy regulators to provide the necessary regulatory clarity on various applications of this technology.
On the political side, governments in the United States and around the world need to consider the thorny governance questions embedded in any conversation about open vs. closed-sourced AI and come to an implementable decision on who should have a stake in controlling and governing the technology. The Biden-Harris Administration should consider what it would look like to push past the principles and practices outlined in initiatives such as the Blueprint for an AI Bill of Rights, Executive Order on AI, AI Risk Management Framework, and draft OMB memo on AI in government and into practical, shared, democratic, and effective governance of dual-use foundation AI models. In the absence of such action, private companies will continue to control and govern advanced AI systems in a closed and undemocratic way. Such a national resource may be too important to cede power to unelected technologists.
We thank the NTIA for opening this RFC and considering our comments in the context of contemplating policy and regulatory recommendations for advanced AI models. We are encouraged by the thought and detail that went into introducing this process to the public and welcome any follow-up that may be useful as you enter the next stage.
1 ⬩ This is responding to Question 1: How should NTIA define “open” or “widely available” when thinking about foundation models and model weights? Subquestion i: Are there promising prospective forms or modes of access that could strike a more favorable benefit-risk balance? If so, what are they?
2 ⬩ Note: We are simplifying some details about how this attestation happens in practice, but the spirit of this statement is reliable.
3 ⬩ This is responding to Question 1: How should NTIA define “open” or “widely available” when thinking about foundation models and model weights?
4 ⬩ There is a longstanding misunderstanding that PETs, such as secure enclaves, cannot scale. While some PETs still have performance challenges, secure enclaves (and their GPU variants) are now operating at comparable performance with industry-standard CPU and GPU chips. We are happy to provide more technical details about enclave performance upon request.
5 ⬩ See Solaiman, I., The Gradient of Generative AI Release: Methods and Considerations, (February 5, 2023)
6 ⬩ See Shevlane, T., et al., Model evaluation for extreme risks, (May 25, 2023).
7 ⬩ This is responding to Question 5: What are the safety-related or broader technical issues involved in managing risks and amplifying benefits of dual-use foundation models with widely available model weights? .
8 ⬩This is responding to Question 5: What are the safety-related or broader technical issues involved in managing risks and amplifying benefits of dual-use foundation models with widely available model weights? Subquestion b: Are there effective ways to create safeguards around foundation models, either to ensure that model weights do not become available, or to protect system integrity or human well-being (including privacy) and reduce security risks in those cases where weights are widely available?
9 ⬩ For more information on retrieval systems please see Borgeaud, S., et al., Improving language models by retrieving from trillions of tokens, (February 7, 2022). Note that this is different from Retrieval-augmented generation (RAG), which only tries to fetch extra relevant information for a context window. The Retrieval-Enhanced Transformer (RETRO) discussed in Boregeaud’s paper may be more capable owing to the model learning to retrieve relevant information as opposed to having information provided by some other mechanism after the fact.