PySyft:
Remote data access with privacy at the core
PySyft is open-source technology that empowers data scientists to perform analyses on sensitive data without compromising confidentiality.
With PySyft, you can:
Collaborate on research projects
Access valuable datasets
Accelerate innovation
PySyft is built on the principles of Remote Data Science, allowing you to send your code to where the data resides and receive only the results of your analysis. This ensures that sensitive information remains protected while still enabling valuable research and collaboration.
How it works
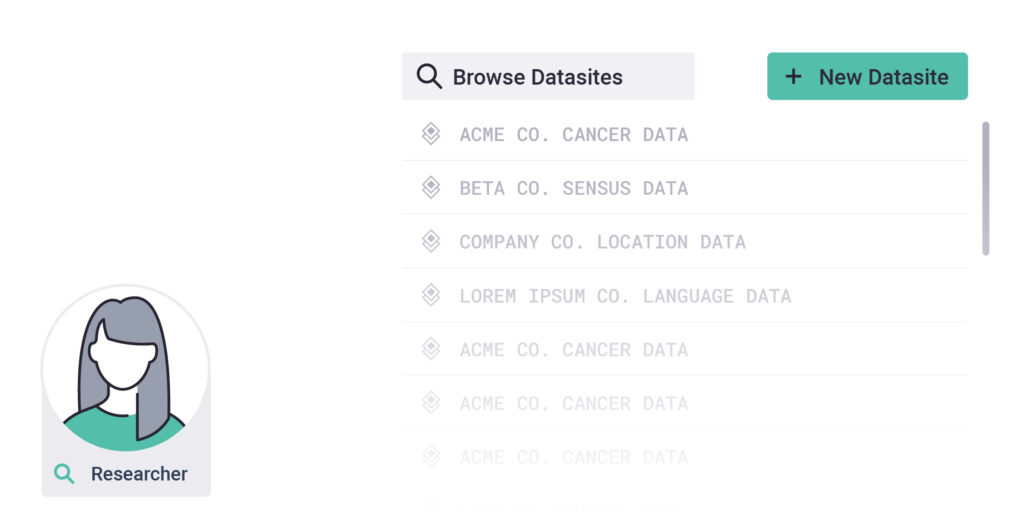
1. Find a Datasite
Browse available datasites or collaborate with a data owner to launch a new one.
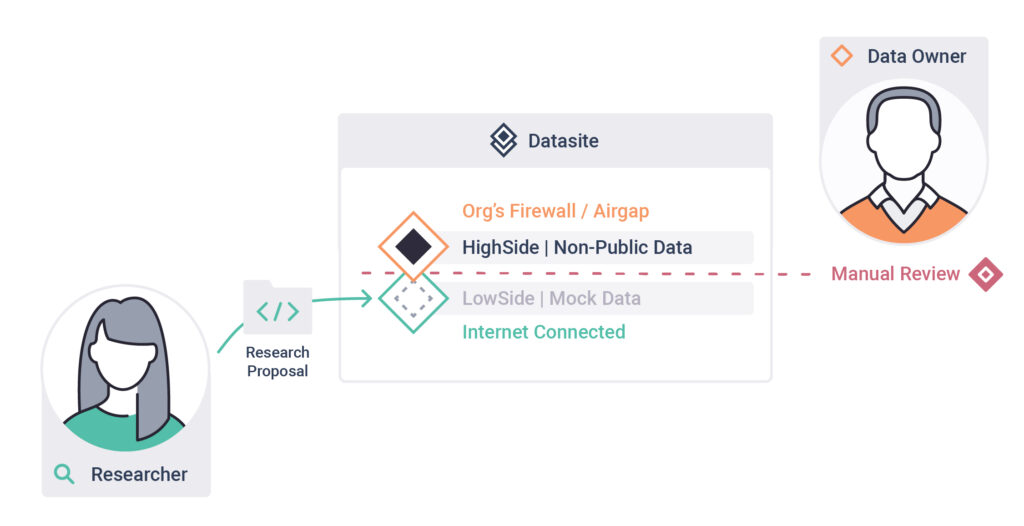
2. Submit a Proposal
Send your research code to the datasite owner for review.
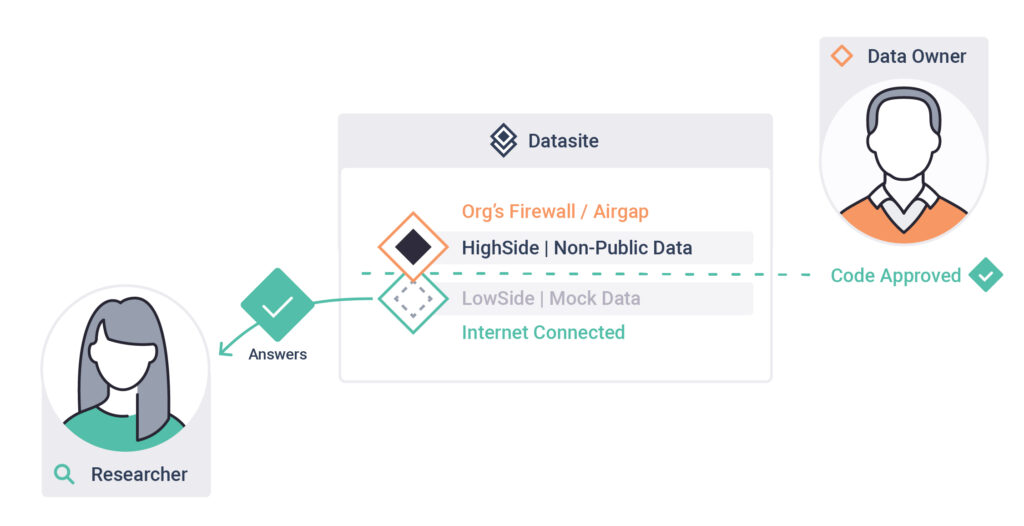
3. Download Results
Once approved by the datasite owner, download the results of your query.
1. Launch a Secure Datasite
Use Syft’s documentation to set up a datasite and load in your data.

2. Review Research Proposals
Evaluate research proposals submitted to your datasite ensuring no sensitive data is compromised.
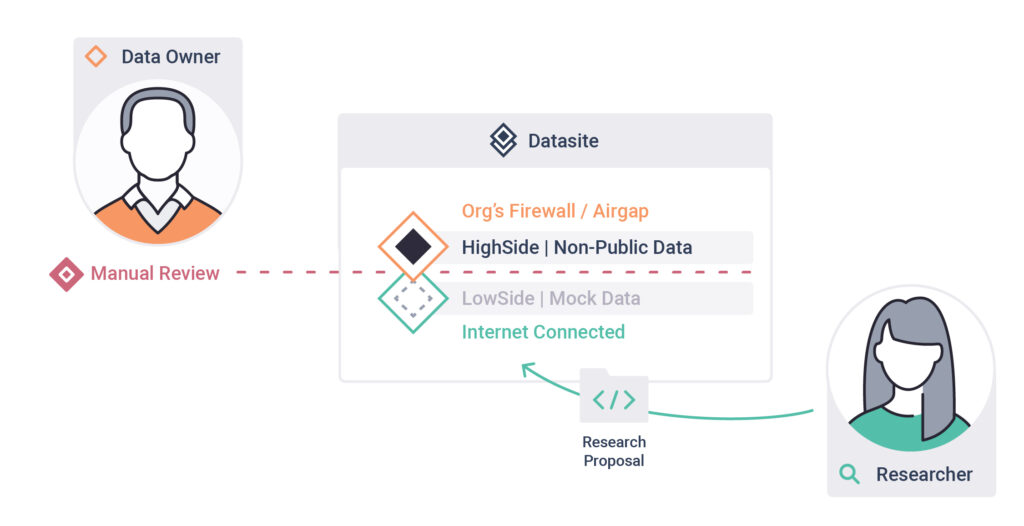
3. Approve compliant projects
Approve the project once it meets your safety standards, allowing the researcher to access the results.
FAQ
How does Syft ensure the analysis doesn’t reveal personal or protected information?
Syft preserves data privacy by enabling data scientists to study data without ever acquiring a copy. In traditional data science flows, researchers see raw private data during the process, which they can copy or remember. Syft avoids this problem, protecting the privacy of the data, through several groundbreaking features it supports:
- Mock-Data-Based Prototyping: The first reason researchers have to look at data is that they need something to use to write their research code. Syft gets around this problem by giving researchers that “something” in a way that preserves privacy — a fake/mock version of the real dataset — identical in every way except the actual values of the data are randomized.
- Manual Code Review: The second reason researchers have to look at data is because they can run any computation on the data and look at the results. Research/data science is inherently iterative, and researchers really want to be able to iterate. Syft gets around the need for researchers to see the data while preserving their ability to iterate. The simplest way Syft does this is by empowering researchers to submit their code — prototyped against mock data — to the data owner’s staff for review and execution.
- Automation Using Privacy-Enhancing Technologies: While the first two features above can (in theory) support any type of researcher accessing any type of dataset without seeing it — it involves researchers waiting for code reviews and data owners spending time reviewing code. Syft overcomes this problem by introducing a variety of privacy-enhancing technologies — access control, federated learning, differential privacy, zero-knowledge proofs, etc. — which enable a data owner to automatically approve some requests, giving researchers instant results and allowing data owners to avoid manual review.
What security measures does Syft implement to ensure that personal or protected information isn’t compromised?
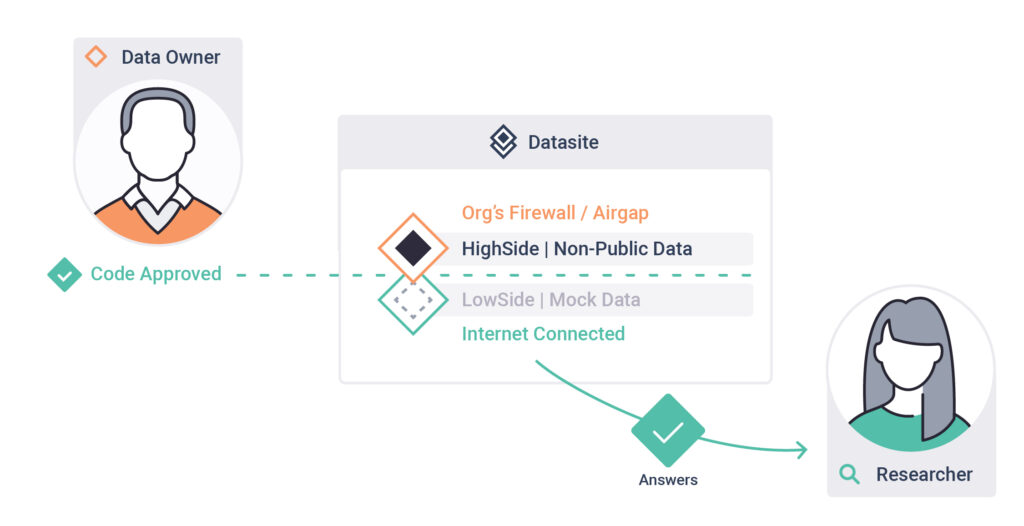
Syft creates solid, traditionally accepted barriers between external researchers and internal computers holding data. In its most secure setting, Syft puts an “air gap” between them, although it can also be configured for a similar “VPN-gapped” configuration.
In these configurations, an internal employee is responsible for moving assets across the “airgap.” Syft provides secure serialization support for objects moving across the “airgap” and convenient triaging to ensure this process is efficient and secure.
In its highest security setting, no research code runs on an organization’s private data without its employees observing every line.
While Syft includes tooling to increase efficiency and provide some automation around the process (approvals, pre-approvals, PETs, etc.), it can do so while upholding this principle.
Where else is Syft deployed?
We have unlocked sensitive user data in places such as Microsoft and GDPR-protected data in areas such as Dailymotion through our partnership with the Christchurch Call Initiative on Algorithmic Outcomes, where external data scientists could perform research on production AI recommender models.
We also have active projects with the US Census Bureau, the Italian National Institute of Statistics (Istat), Statistics Canada (StatCan), and the United Nations Statistics Division (UNSD) to demonstrate how joint analysis across restricted statistical data can work internationally across national statistics offices.
Additionally, we have an active project with the xD team at the US Census Bureau to help make their Title-13 and Title-26 protected data available for research.
We are also the infrastructure of choice for Reddit’s external researcher program.
Get PySyft Updates
Sign up to get updates from OpenMined’s Product & Engineering teams.
This will subscribe you to Product & Protocol News. What to change that later? Use link at the bottom of our emails.
Subscribing confirms you agree with our privacy policy.
Ready to experience privacy-preserving collaboration?
Visit the PySyft documentation to started today!