
TL;DR: Publishers, creators and AI labs are stuck in an impasse that benefits neither. Current responses – blocking, licensing, pay-to-access – share a common limitation: once content is copied, control and attribution are lost. This reduces creators’ ability to capture value from their work. But the assumption that content distribution and control are mutually exclusive is no longer true. A different architecture exists, one where publishers retain control, AI systems get sustainable access, and value flows back to those who create it. It’s live and piloting now.
⬩⬩⬩
For twenty years, publishers operated under an implicit bargain: indexing for traffic. Search engines indexed content and sent readers back. While imperfect, it is legible: publishers could model it, monetize it, and opt out.
AI breaks this arrangement: it doesn’t just index content to point users towards it, but ingests content to answer users directly. Cloudflare’s 2025 data captures this asymmetry: Anthropic’s bot crawls a site 38,000 times for every single referral returned. OpenAI’s ratio was 1,091 to 1. Roughly 80% of crawling now serves model training, not search. [1] [2]
Maria Ressa, Nobel laureate journalist, captures the sentiment spreading through newsrooms: “Everything we knew as an industry has been destroyed.” [3] But the crisis extends beyond journalism. The architecture that creates this imbalance – the mathematical operations underlying modern AI – creates consequences that cascade through every level of the information economy.
This piece explains the technical implications and introduces a framework to overcome it: attribution-based control.
This is part one of a series exploring how publishers can reclaim agency in the AI economy through technical leverage, public infrastructure and working collectively.
Sign up to be notified of follow-up parts.
⬩⬩⬩
This Isn’t Just a News Problem
News gets the headlines, but every information market faces the same disruption:
- Trade and educational publishers see reference works summarized without attribution [4]. By providing direct answers, AI removes the need to consult the original content.
- Academic publishers face large-scale ingestion of journals [5] and verifiable “sources of truth” get replaced by probabilistic, anonymous summaries that infiltrate research pipelines and undermine future scholarship.
- Book and niche publishers watch catalogs absorbed into systems that compete with their own products [6]. Lacking the leverage to negotiate, they are cut out of the loop entirely.
What unites them all: none have the infrastructure to maintain control or capture value where it’s actually created. This isn’t a legal problem, but a technical one.
Rights Exist. Enforcement Does Not.
Publishers possess an arsenal of legal protections: copyright, terms of service, licensing frameworks, contracts. However, their effectiveness depends entirely on technical enforcement.
Consider robots.txt, proposed in 1994 as a voluntary standard rooted in the assumption that “machines could be taught to listen to human intent and choose to honor it.”[7] They don’t:
- 13% of AI bot requests ignored robots.txt directives in Q2 2025 [8]
- Perplexity continued accessing content “even after being blocked,” deploying disguised crawlers [9]
- 89% of domains block GPTBot overall, summing up to 5.6M websites [10, 11]
The fundamental issue: robots.txt is a polite request, not enforceable. Tools like Cloudflare empower publishers to stop bots at the gate, but once data is scraped, publishers lose all control over all its future uses. This is “use bundling” – the technical inability to separate how data is used once obtained. Publishers cannot specify:
- “Yes to inference, no to training”
- “Paying Lab A yes, but Lab B no”
- “Yes for news summarization, no for competing content generation.”
This “all-or-nothing” reality creates a widening gap between legal contracts and technical enforcement. While over 70 copyright lawsuits remain pending, crawlers continue operating without constraints.[12][13].
But even if every lawsuit succeeds, the deeper issue remains: the architecture of AI itself makes governance impossible.
The Hidden Technical Reality
Two fundamental properties of modern AI make traditional governance impossible, regardless of litigation outcomes: the copy problem and distillation problem.
The copy problem
Training requires a full copy of content to move permanently to the developer’s servers. Once copied, publishers retain theoretical rights but lose practical control: no transparency into usage, no compliance verification, no ability to withdraw.
The distillation problem
Moreover, contrary to the “learning” metaphor, models memorize. Stanford and Yale research shows Claude and GPT can reproduce near-complete books [14]: they store recoverable sequences, not just abstract patterns. Yet even when models memorize exactly, they cannot preserve attribution.
Why? AI training is designed for distillation, not discovery. Think of it as a telephone system. Search engines work like a phone book – you can trace every call back to a specific number. AI training works like a party line where millions of conversations get mixed into one signal. You hear the information, but can’t tell who said what. This process—converting your data into “gradient updates” and adding them to the model’s weights—creates what Ted Chiang called a “blurry JPEG of the web.” [15]
This creates three massive problems for publishers:
- Data is decoupled from metadata: Even when models memorize high-value texts, current architectures do preserve author names or URLs [16]
- Post-training traceability fails: Tools designed to trace AI output back to training sources (“influence functions”) are notoriously unstable and fail in large models.[17][18][19] A few startups like ProRata rely on such “Shazam”-like methods.
- The “unlearning” barrier: There’s no undo button. Removing specific content from a trained model risks breaking the model itself.[20] Your contribution can’t be isolated, measured, or fairly compensated.
The architectural deadlock: the blending that makes AI useful is exactly what severs the link back to publishers.
The Distribution-Control Trade-off
Historically, information markets operated on an implicit bargain: sacrifice control for distribution. New technologies offered reach in exchange for governance.
This trade-off matters because those who control distribution capture value; those who create it often do not. Value – the benefit generated when information answers a question – flows to those who process and deliver it, rarely to those who originated it. Market price captures only a fraction of this value, and only when creators have the technical leverage to demand it.
The bargain has evolved through distinct phases:
- The printing press expanded distribution but concentrated control over it [21]. Press owners captured value; authors traded one patron for another. Copyright attempted to make it fair—and for two centuries, it largely did. Creators gained a legal claim on distribution, letting them share in the value. And crucially, readers were still reached: the audience arrived at the source.
- Social media repeated the pattern. New technology created new distribution channels, but publishers and authors remained outside the control loop. Copyright helped at the margins, but platforms held the leverage. When Facebook’s 2016 “pivot to video” collapsed—built on metrics inflated by 150–900%[22][23]—publishers like Mic and Vocativ had no recourse. By 2024, Facebook referrals to news sites had plunged 58%.[24] Still, readers were reached: they followed links, visited sites, saw the source.
- AI completes the cycle towards disintermediation by appropriating “all the information assembled collectively.”[21] Unlike previous eras where the creator still met the reader at the end of the journey, AI provides the answer directly.
If social media strained the bargain, AI has broken it: the reach no longer justifies the loss of control because the audience relationship is severed entirely – the author is forgotten, benefiting neither financially nor in terms of a relationship with the beneficiaries of her work.
However, the same technology that enables disintermediation can also enable total participation. But first, let’s examine why current responses fail to solve this problem.
Why Current Defenses Fail
Understanding this pattern clarifies why current responses are inadequate:
Blocking protects principle but sacrifices reach. 80% of major news publishers now block AI crawlers,[25][26] yet a Rutgers/Wharton study found that blocking cost publishers 23% of total traffic and 14% of human traffic; protecting content “actually harmed traffic more than allowing access.”[27] Meanwhile, AI and search are becoming structurally intertwined: Google’s AI Overviews now appear in standard results; Microsoft’s Bing has become Copilot Search.[28] Block the crawler means disappearing from discovery. The problem isn’t blocking itself – it’s that no secondary distribution exists. Publishers face a binary choice: block and lose reach, or allow access and lose control.
Full Access Licensing generates real revenue: News Corp received $250 million over five years from OpenAI; the Financial Times gets $5-10 million annually.[29] But once access is granted, the AI lab uses data however it wishes. No ongoing relationship, no visibility into usage, no attribution, no ability to adjust terms. Data is priced as a commodity, not a continuing contributor to value. License once, lose control forever: your content gets copied, and governance passes to the licensee.
Pay-to-access services like Tollbit and Cloudflare sit between publishers and crawlers, charging for access. [30] But pricing remains opaque and disconnected from actual usage; crawlers can still bypass the system entirely. Your content still gets copied in full: you’ve just added a toll booth before extraction. Once copied, there’s no reclaiming it. And the intermediary becomes a centralized gatekeeper, positioned to dictate how the market develops.
All three approaches accept the same assumption: distribution and control are mutually exclusive.
However, that assumption is no longer true.
A Different Architecture
Whether AI systems rely on training, retrieval, or both, they share the same structural flaw: centralized control with the illusion of comprehensiveness. Training dissolves sources into weights – attribution becomes impossible by design. Retrieval appears better but isn’t: AI companies control what gets indexed, what gets surfaced, what gets suppressed.
But the deepest problem sits with users. They assume they’re querying “the internet” or “general knowledge”- not a curated subset shaped by decisions they cannot see. They receive an answer and have no reason to look further.
Think of it as a telephone without a dial pad. You pick up and someone answers, but you didn’t choose who. The people whose knowledge you’re hearing have no idea they’re being used. You can’t verify sources or build relationships with those you trust.
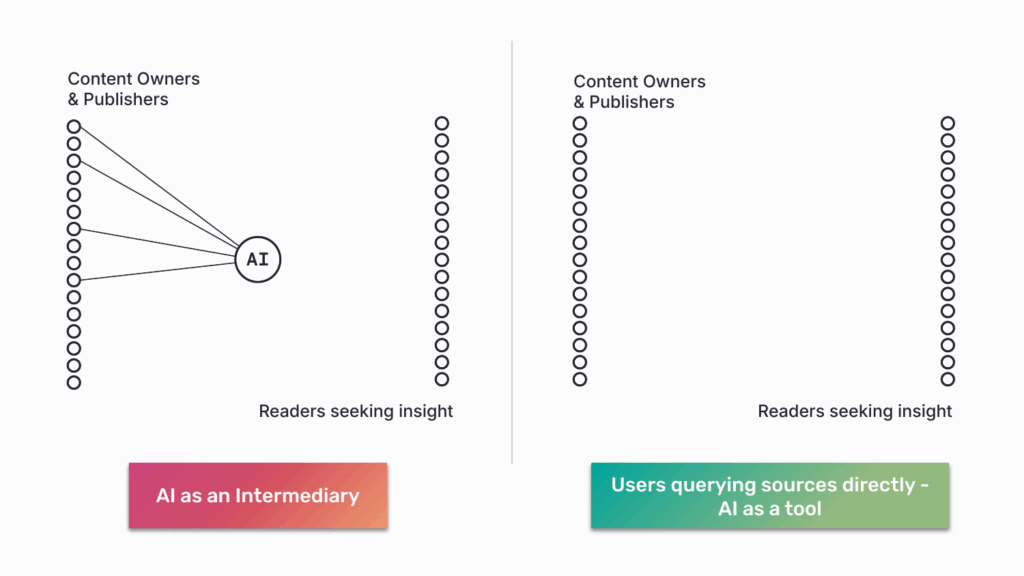
Attribution-Based Control: Restoring the Dial Pad
- Users choose their sources: Cast a wide net (“all news sources”), narrow it (“only peer-reviewed journals”), or query specific sources (“FT’s perspective”). Sources are visible, selection is transparent.
- Publishers control each interaction: Not one-time licensing that surrenders future governance, but dynamic, per-query control. Who accesses? On what terms? At what price? With what attribution?
This is the dial pad. Users call who they want. Publishers decide whether to answer.
The Core Principles
This is the only architecture that preserves publisher agency. Attribution-based control (ABC) requires two conditions:
1. Publishers control their contribution. They govern how much intelligence to give each AI request they support – not a blanket yes or no, but fine-grained, real-time, revocable.
2. Users control their sources. They dynamically choose which publishers they want to rely on for each query, not whatever the system absorbed during training, but specific, visible, accountable sources.
For this to work, content must remain separable: not dissolved into weights, not hidden in someone else’s index.
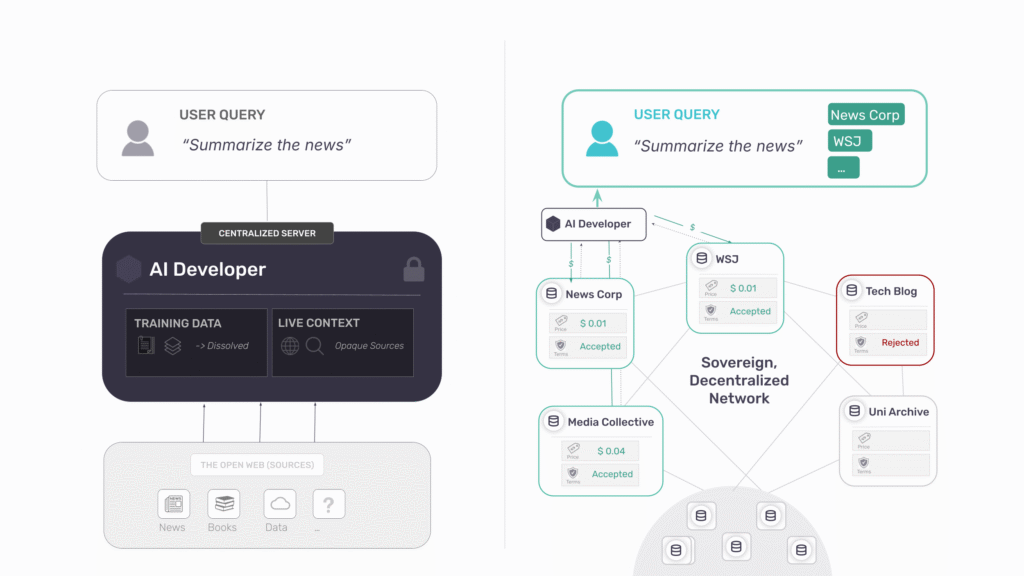
This directly addresses the two problems we identified:
- The copy problem disappears because content never leaves the publisher’s infrastructure – queries come to you; your data doesn’t go to them. Revoke access instantly; there’s nothing to delete from someone else’s servers.
- The attribution problem disappears because the link between query and source is preserved by architecture, not goodwill. Every response that draws on your content must cite it—not because the AI company chose to, but because the system cannot function otherwise.
ABC breaks the distribution-control trade-off. Publishers gain distribution while retaining control. So how does this work in practice?
The Protocol: Syft
OpenMined, a global nonprofit, built the Syft Protocol as open infrastructure for ABC. It’s piloting now with news publishers, book publishers, and academic institutions.[31]
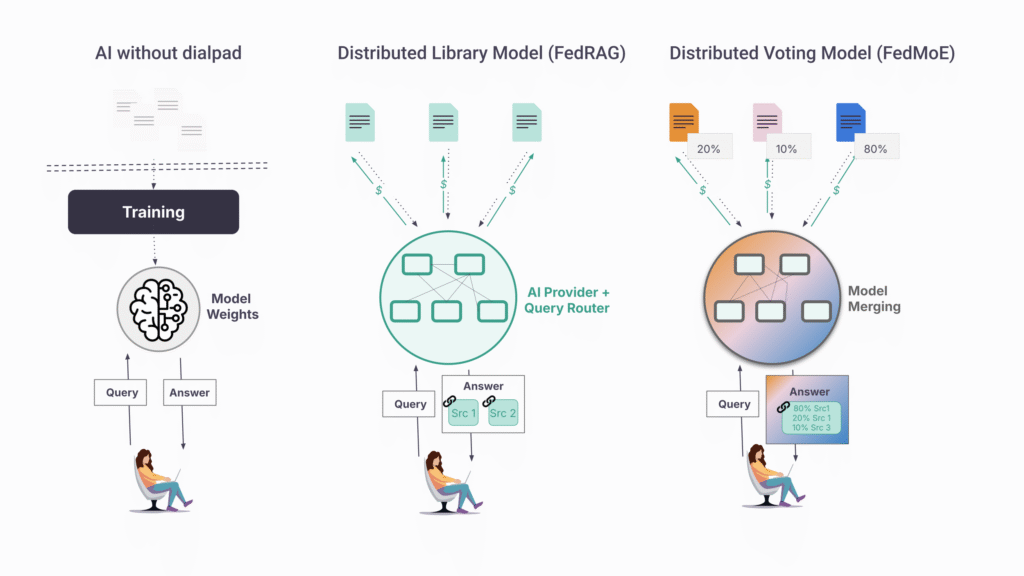
How it works:
- Content stays at source. Your data remains on your servers. Local processing makes it queryable without making it extractable. Nothing gets copied.
- Queries come to you. When an AI system needs your content, the request arrives at your infrastructure in real time. You see who’s asking. You can enforce KYC requirements, rate limits, or human review before responding.
- You set and enforce terms. Pricing, access controls, usage restrictions—applied per query, not negotiated once and forgotten. Terms can differ by requester, by use case, by volume.
- Attribution is structural. Responses cite sources because the architecture requires it. Payment flows because usage is logged at the source
Collective Power
A single publisher negotiating alone is easy to ignore. The protocol enables collective governance: trade associations, regional alliances, academic consortia, creator unions. Members pool content, negotiate shared terms, and distribute revenue by contribution. To AI systems, the collective appears as a single source—small publishers gain the same leverage as large ones. Part 3 of this series explores how collective bargaining reshapes the power dynamics.
Why AI Developers Will Adopt This
The data that differentiates AI systems (real-time information, paywalled archives, verified expertise) cannot be scraped. ABC offers what adversarial scraping never can: sustainable, legal access to the highest-quality sources. Part 2 explains why AI labs will adopt this: not out of principle, but because the best data requires it.
Public Infrastructure
The web is open because HTTP was built as public infrastructure, not a product. Mobile and social are closed because open protocols came too late.[32] The protocols governing AI must be public: they determine whether information flows openly or through centralized pipelines where creators disappear.
That’s why we’re building Syft as open-source infrastructure, not a proprietary intermediary. No one decides who participates or on what terms. Content owners set their own terms; AI developers access content through open APIs. The protocol coordinates; it does not control. This is public infrastructure for the AI era.
The Path Forward
The crisis facing publishing is not that AI uses content – it’s that publishers have no role in the moment value is created. The choice is here:
- Remain passive suppliers: sell access while losing audience, attribution, and long-term leverage.
- Become active participants in AI infrastructure who retain control, preserve visibility, and capture recurring value at the moment of inference every time your content informs an answer.
AI will reshape publishing whether publishers participate or not. The question is whether they remain raw material—or participate in the public infrastructure that governs how their work is used.
For publishers who would like to learn more: reach out!
For AI developers seeking sustainable access to high-quality data: The protocol is open and docs are available here.
For those who believe AI should be built on public infrastructure: we need contributors, advocates, and allies. Come build with us.
If you would like to be notified for the upcoming parts or participate in the conversation, sign-up for our newsletter and shoot us a message:
References
[1]: Cloudflare Blog, “The crawl-to-click gap: Cloudflare data on AI bots, training, and referrals,” 2024
[3]: Maria Ressa quote (LinkedIn post)
[5]: Nature, “AI firms must play fair when they use academic data in training,” 2024.
[6]: Authors Guild, “Understanding the AI Class Action Lawsuits,” 2024.
[7]: Chevan Nanayakkara, “Robots.txt: The Birth of the Agentic Internet,” Medium, June 2025
[8]: Tollbit AI Bot Traffic Report, Q2 2024.
[9]: New York Times v. Perplexity AI, complaint filed December 2025, Southern District of New York.
[10]: Paul Calvano, “AI Bots and Robots.txt,” August 2025
[11]: Ahrefs Blog, “The AI Bots That ~140 Million Websites Block the Most,” 2024
[12]: McKool Smith, “AI Litigation Tracker,” updated 2025
[14]: Alex Reisner, “AI’s Memorization Crisis,” The Atlantic, January 2026
[15]: Ted Chiang, “ChatGPT Is a Blurry JPEG of the Web,” The New Yorker, February 2023
[17]: Zhu and Cangelosi, “Revisiting Data Attribution for Influence Functions,” arXiv, August 2025
[19]: Li et al., “Do Influence Functions Work on Large Language Models?,” arXiv, September 2024
[20]: “Machine Unlearning in Large Language Models: A Comprehensive Survey,” LessWrong, 2024
[21]: Matt Prewitt, “The Models Are Yours: The Public’s Leverage in AI,” RadicalxChange, January 2024 [22]: Variety, “Facebook to Pay $40 Million to Settle Claims It Inflated Video Viewing Data,” 2019
[25]: Press Gazette, “Eight in ten of world’s biggest news websites now block AI training bots,” 2024
[26]: Reuters Institute, Richard Fletcher, “How many news websites block AI crawlers?” February 2024
[28]: Microsoft, “Your AI Companion” (Copilot Search in Bing announcement), April 2025
[29]: Variety, “News Corp Inks OpenAI Licensing Deal Worth More Than $250 Million,” May 2024
[31]: OpenMined, “Syft For Publishers [Beta],” 2024
[32]: W3C, Tim Berners-Lee, “A Little History of the World Wide Web”